
Table of Links
4 Human Evaluations and Safety Testing, and 4.1 Prompts for Evaluation
5 Benchmark Evaluations and 5.1 Text
7 Conclusion, Acknowledgements, Contributors, and References
Appendix
B. Additional Information of Human Evaluations
2.3 Stability
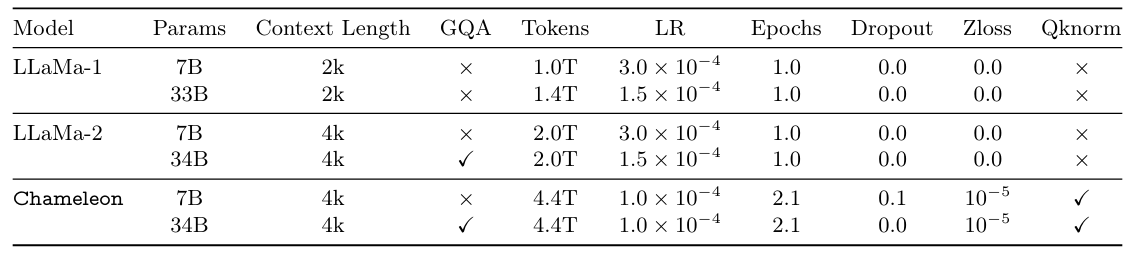
It was challenging to maintain stable training when scaling the Chameleon models above 8B parameters and 1T tokens, with instabilities often only arising very late in training. We adopted to following recipe for architecture and optimization to achieve stability.
Architecture Our architecture largely follows LLaMa-2 (Touvron et al., 2023). For normalization, we continue to use RMSNorm (Zhang and Sennrich, 2019); we use the SwiGLU (Shazeer, 2020) activation function and rotary positional embeddings (RoPE) (Su et al., 2021).
We found that the standard LLaMa architecture showed complex divergences due to slow norm growth in the mid-to-late stages of training. We narrowed down the cause of the divergence to the softmax operation being problematic when training with multiple modalities of significantly varying entropy due to the translation invariant property of softmax (i.e., softmax(z) = softmax(z + c)). Because we share all weights of the model across modalities, each modality will try to “compete” with the other by increasing its norms slightly; while not problematic at the beginning of training, it manifests in divergences once we get outside the effective representation range of bf16 (In Figure 6b, we show that ablations without image generation did not diverge). In a unimodal setting, this problem has also been named the logit drift problem (Wortsman et al., 2023). In Figure 5a, we plot the norms of the output of the last transformer layer as training progresses and we find that although training divergences can manifest after as much as even 20-30% of training progress, monitoring uncontrolled growth of output norms is strongly correlated with predicting future loss divergence.
The softmax operation appears in two places in transformers: the core attention mechanism and the softmax over the logits. As inspired by Dehghani et al. (2023) and Wortsman et al. (2023), we first deviate from the Llama architecture by using query-key normalization (QK-Norm). QK-Norm directly controls the norm growth of input to the softmax by applying layer norm to the query and key vectors within the attention.
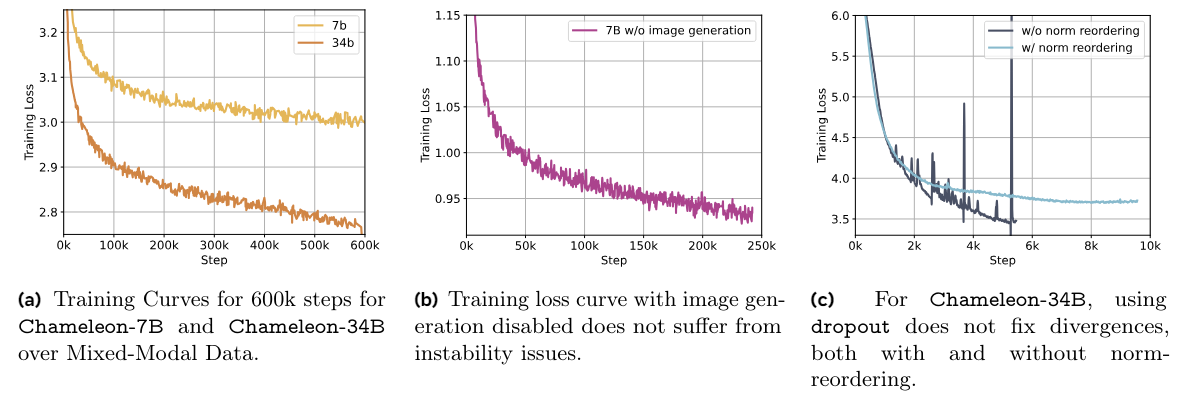
In Figure 5b, we show training loss curves for Chameleon-7B with and without QK-Norm, and the latter diverges after approximately 20% of a training epoch.
We found that to stabilize Chameleon-7B by controlling norm growth, it was necessary to introduce dropout after the attention and feed-forward layers, in addition to QK-norm (see Figure 5c). However, this recipe was not enough to stabilitize, Chameleon-34B, which required an additional re-ordering of the norms. Specifically, we use the strategy of normalization proposed in Liu et al. (2021), within the transformer block. The benefit of the Swin transformer normalization strategy is that it bounds the norm growth of the feedforward block, which can become additionally problematic given the multiplicate nature of the SwiGLU activation function. If h represents the hidden vector at time-step t after self-attention is applied to input x,

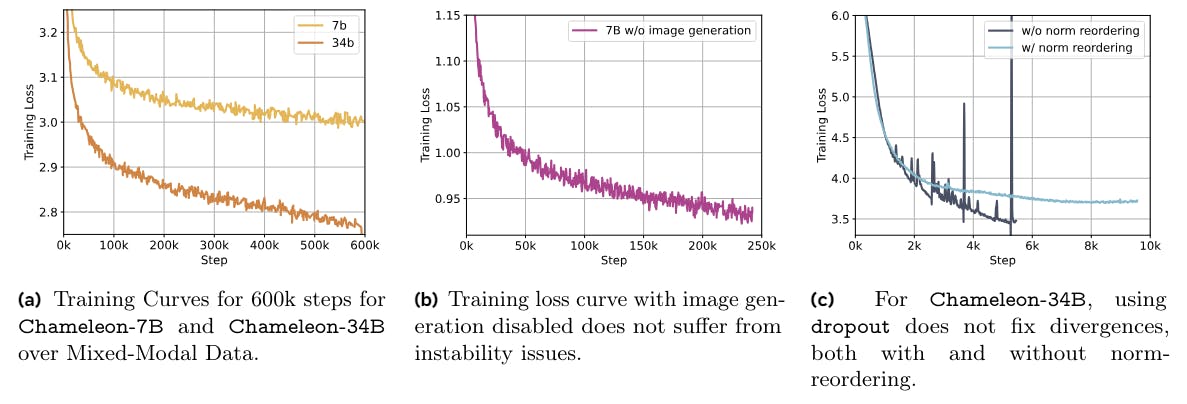
There was no difference in perplexity when training a model from scratch with and without the normalization re-ordering until the divergence of the LLaMa-2 parameterization. Additionally, we found that this type of normalization did not work well in combination with dropout and therefore, we train Chameleon-34B without dropout (Figure 6c). Furthermore, we retroactively found that Chameleon-7B can also be stably trained without dropout, when using norm-reordering, but QK-norm is essential in both cases. We plot training curves for the first 600k steps for both Chameleon-7B and Chameleon-34B in Figure 6a.

Pre-Training Hardware Our model pretraining was conducted on Meta’s Research Super Cluster (RSC) (Lee and Sengupta, 2022), and our alignment was done on other internal research clusters. NVIDIA A100 80 GB GPUs power both environments. The primary distinction is the interconnect technology: RSC employs NVIDIA Quantum InfiniBand, whereas our research cluster utilizes Elastic Fabric. We report our GPU usage for pre-training in Table 2.

2.4 Inference
To support alignment and evaluation, both automated and human, and to demonstrate the application-readiness of our approach, we augment the inference strategy with respect to interleaved generation to improve throughput and reduce latency.
Autoregressive, mixed-modal generation introduces unique performance-related challenges at inference time. These include:
• Data-dependencies per-step — given that our decoding formulation changes depending on whether the model is generating images or text at a particular step, tokens must be inspected at each step (i.e. copied from the GPU to the CPU in a blocking fashion) to guide control flow.
• Masking for modality-constrained generation — to facilitate exclusive generation for a particular modality (e.g. image-only generation), tokens that do not fall in a particular modality space must be masked and ignored when de-tokenizing.
• Fixed-sized text units — unlike text-only generation, which is inherently variable-length, token-based image generation produces fixed-size blocks of tokens corresponding to an image.
Given these unique challenges, we built a standalone inference pipeline based on PyTorch (Paszke et al., 2019) supported with GPU kernels from xformers (Lefaudeux et al., 2022).
Our inference implementation supports streaming for both text and images. When generating in a streaming fashion, token-dependent conditional logic is needed at each generation step. Without streaming, however, blocks of image tokens can be generated in a fused fashion without conditional computation. In all cases, token masking removes branching on the GPU. Even in the non-streaming setting, however, while generating text, each output token must be inspected for image-start tokens to condition image-specific decoding augmentations.
Author:
(1) Chameleon Team, FAIR at Meta.
This paper is