
Author:
(1) Chameleon Team, FAIR at Meta.
Table of Links
4 Human Evaluations and Safety Testing, and 4.1 Prompts for Evaluation
5 Benchmark Evaluations and 5.1 Text
7 Conclusion, Acknowledgements, Contributors, and References
Appendix
B. Additional Information of Human Evaluations
We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach from inception, an alignment recipe, and an architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation. Chameleon demonstrates broad and general capabilities, including state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model. It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation, where either the prompt or outputs contain mixed sequences of both images and text. Chameleon marks a significant step forward in a unified modeling of full multimodal documents
1 Introduction
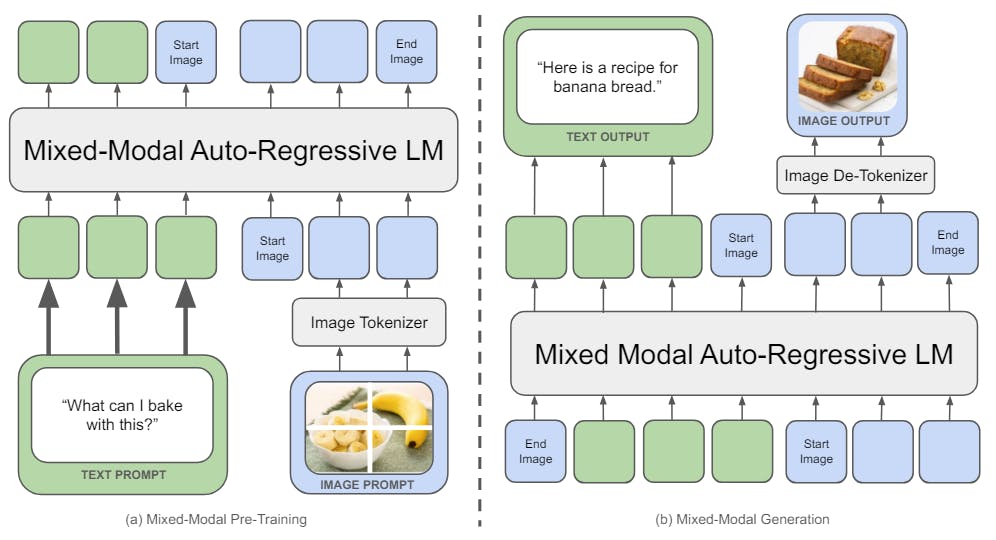
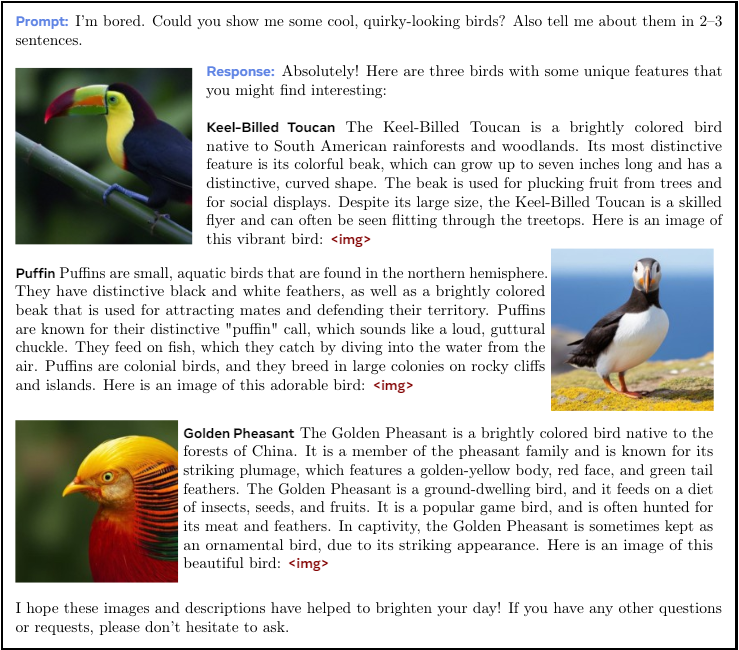
Recent multimodal foundation models are very widely adopted but still model different modalities separately, often using modality specific encoders or decoders. This can limit their ability to integrate information across modalities and generate multimodal documents that can contain arbitrary sequences of images and text. In this paper, we present Chameleon, a family of mixed-modal foundation models capable of generating and reasoning with mixed sequences of arbitrarily interleaved textual and image content (Figures 2-4). This allows for full multimodal document modeling, which is a direct generalization of standard multimodal tasks such as image generation, understanding and reasoning over images, and text-only LLMs. Chameleon is instead designed to be mixed-model from inception and uses a uniform architecture trained from scratch in an end-to-end fashion on an interleaved mixture of all modalities, i.e., images, text, and code.
Our unified approach uses fully token-based representations for both image and textual modalities (Figure 1). By quantizing images into discrete tokens, analogous to words in text, we can apply the same transformer architecture to sequences of both image and text tokens, without the need for separate image/text encoders (Alayrac et al., 2022; Liu et al., 2023b; Laurençon et al., 2023) or domain-specific decoders (Ramesh et al., 2022; Jin et al., 2023; Betker et al., 2023). This early-fusion approach, where all modalities are projected into a shared representational space from the start, allows for seamless reasoning and generation across modalities. However, it also presents significant technical challenges, particularly in terms of optimization stability and scaling.
We address these challenges through a combination of architectural innovations and training techniques. We introduce novel modifications to the transformer architecture, such as query-key normalization and revised placement of layer norms, which we find to be crucial for stable training in the mixed-modal setting (Section 2.3). We further show how to adapt the supervised finetuning approaches used for text-only LLMs to the mixed-modal setting, enabling strong alignment at scale (Section 3). Using these techniques, we successfully train Chameleon-34B on 5x the number of tokens as Llama-2 – enabling new mixed-modal applications while still matching or even outperforming existing LLMs on unimodal benchmarks.
Extensive evaluations demonstrate that Chameleon is a broadly capable model on a diverse set of tasks. On visual question answering and image captioning benchmarks, Chameleon-34B achieves state-of-the-art performance, outperforming models like Flamingo, IDEFICS and Llava-1.5 (Section 5.2). At the same time, it maintains competitive performance on text-only benchmarks, matching models like Mixtral 8x7B and Gemini-Pro on commonsense reasoning and reading comprehension tasks (Section 5.1). But perhaps most impressively, Chameleon unlocks entirely new capabilities in terms of mixed-modal reasoning and generation.
As using only static, public benchmarks to evaluate model performance could be limited (Schaeffer, 2023), we also conduct a carefully designed human evaluation experiment by measuring the quality of mixed-modal long form responses to open-ended prompts. Chameleon-34B substantially outperforms strong baselines like Gemini-Pro and GPT-4V (Section 4), achieving a 60.4% preference rate against Gemini-Pro and a 51.6% preference rate against GPT-4V in pairwise comparisons.
In summary, we present the following contributions:
• We present Chameleon, a family of early-fusion token-based mixed-modal models capable of reasoning over and generating interleaved image-text documents, setting a new bar for open multimodal foundation models.
• We introduce architectural innovations and training techniques that enable the stable and scalable training of early-fusion token-based models, addressing key challenges in mixed-modal learning.
• Through extensive evaluations, we demonstrate state-of-the-art performance across a diverse set of vision-language benchmarks, while maintaining competitive performance on text-only tasks, and high quality image generation, all in the same model.
• We conduct the first large-scale human evaluation on open-ended mixed-modal reasoning and generation, demonstrating the unique capabilities of Chameleon in this new setting.
Chameleon represents a significant step towards realizing the vision of unified foundation models capable of flexibly reasoning over and generating multimodal content.
This paper is