

Chameleon Sets New Benchmarks in AI Image-Text Tasks
20 May 2025
Chameleon’s unified token-based model excels at integrating images and text, setting new performance standards across multimodal AI tasks.

How Chameleon Advances Multimodal AI with Unified Tokens
20 May 2025
Chameleon unifies image and text tokens in one model, advancing AI’s ability to understand and generate mixed-modal content seamlessly.

Comparing Chameleon AI to Leading Image-to-Text Models
20 May 2025
Chameleon AI matches or outperforms larger models in image captioning and visual question answering with fewer training examples.

Chameleon AI Shows Competitive Edge Over LLaMa-2 and Other Models
20 May 2025
Chameleon AI outperforms LLaMa-2 and rivals top models in commonsense, math, and world knowledge benchmarks, thanks to enhanced training and data quality.
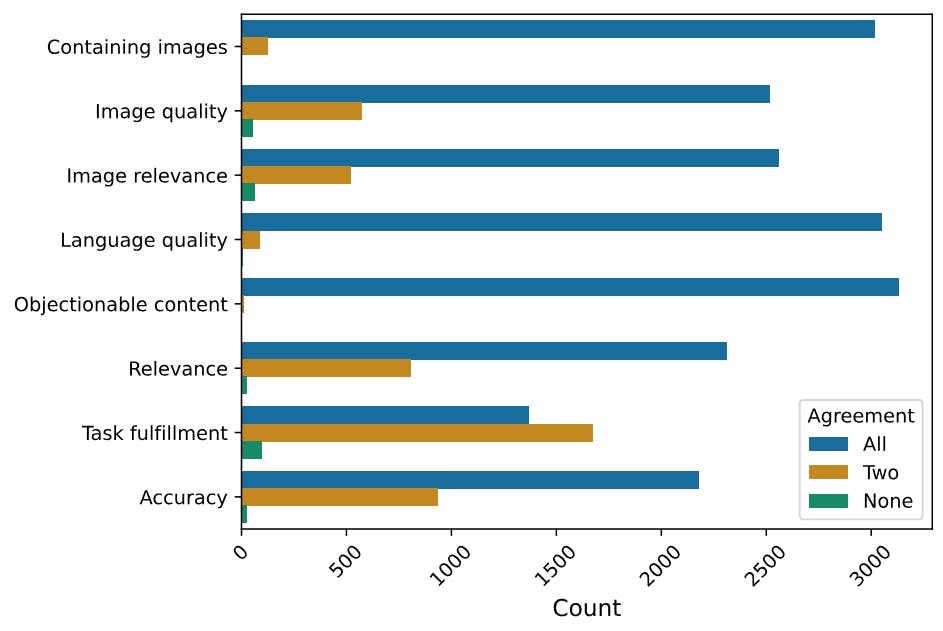
How Reliable Are Human Judgments in AI Model Testing?
19 May 2025
Chameleon AI shows strong safety and mixed-modal performance, with most human evaluations in agreement and minimal unsafe content generation.
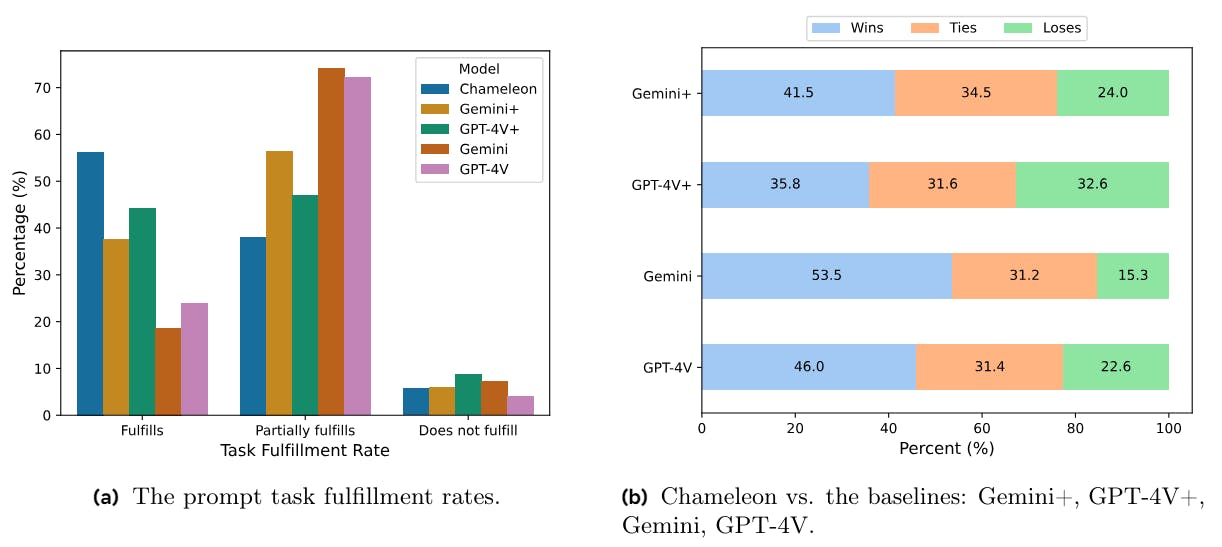
Comparing Chameleon with GPT-4V and Gemini
19 May 2025
Chameleon outperforms GPT-4V and Gemini in human evaluations, showing better task fulfillment in mixed-modal AI understanding and generation.

Inside the Multi-Modal Training That Powers Safer AI
18 May 2025
How multi-modal data and supervised fine-tuning improve AI safety, performance, and response quality across text, code, and image tasks.
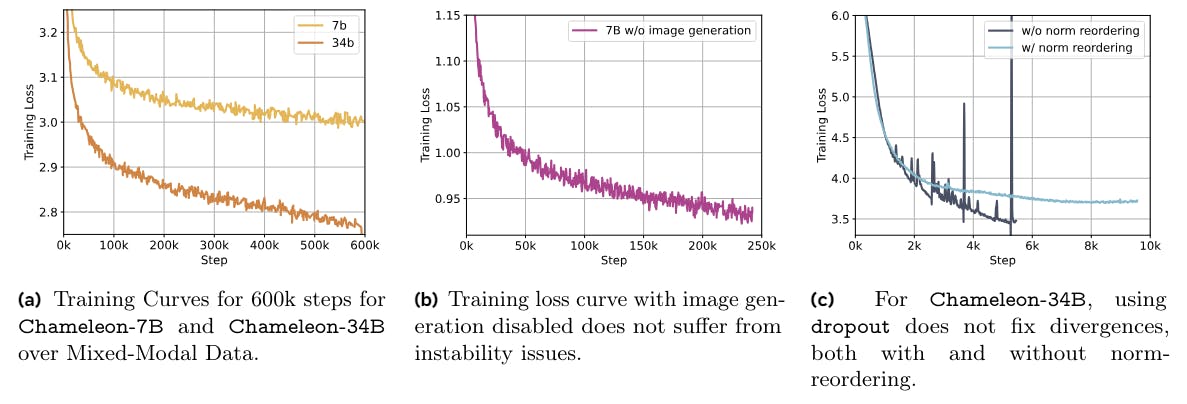
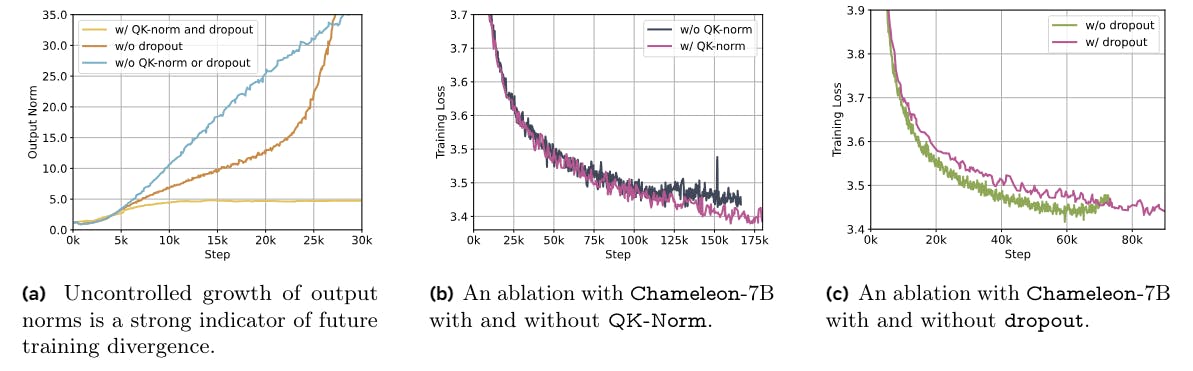
Overcoming Training Hurdles in Multimodal AI Models
18 May 2025
Chameleon models tackle training instability with QK-Norm, norm reordering, and dropout tweaks to support scalable, multimodal AI generation.
How Chameleon AI Can Understand Images and Text Together
18 May 2025
Chameleon is trained on trillions of tokens from text and images using smart tokenization and a two-stage data strategy for rich multimodal learning.